


文章详情
备受瞩目的中国人工智能研究实验室DeepSeek AI,继其强大的开源语言模型DeepSeek-R1之后,再次在大型语言
2025-04-28 21:32:35
文章详情介绍
备受瞩目的中国人工智能研究实验室DeepSeek AI,继其强大的开源语言模型DeepSeek-R1之后,再次在大型语言模型(LLM)领域取得重大突破。近日,DeepSeek AI正式推出一项名为自主演原则的批判调优(Self-Principled Critique Tuning,简称SPCT)的创新技术,旨在构建更通用、更具扩展性的AI奖励模型(Reward Models,简称RMs)。这项技术有望显著提升AI在开放式任务和复杂环境中的理解和应对能力,为更智能的AI应用铺平道路。
背景:奖励模型——强化学习的“指路明灯”
在开发先进的LLM的过程中,强化学习(Reinforcement Learning,简称RL)已成为一项关键技术。RL通过引入反馈信号来指导模型的微调,使其能够生成更高质量的回复。而在这个过程中,奖励模型扮演着至关重要的角色,如同一个“裁判”,负责评估LLM的输出并给出相应的分数或“奖励”。这些奖励信号能够有效地引导RL过程,促使LLM学习产生更有用的内容。
然而,当前的奖励模型也面临着诸多限制。它们往往在规则明确或答案易于验证的狭窄领域表现出色,例如DeepSeek-R1等模型在数学和编程问题上的优秀表现就得益于在此类问题上明确的“正确答案”。但是,对于复杂、开放或主观性较强的一般领域查询,构建一个有效的奖励模型仍然是一个巨大的挑战。DeepSeek AI的研究人员在其论文中指出:“通用奖励模型需要在特定领域之外生成高质量的奖励,而这些领域的奖励标准更加多样和复杂,并且往往没有明确的参考或标准答案。”
SPCT:应对四大挑战,打造通用奖励模型
为了克服现有奖励模型的局限性,DeepSeek AI的研究人员提出了SPCT这一全新的技术。他们强调了构建通用奖励模型需要应对的四个关键挑战:
- 输入灵活性(Input flexibility): 奖励模型必须能够处理各种不同的输入类型,并能够同时评估一个或多个回复。
- 准确性(Accuracy): 在标准复杂且缺乏明确答案的各种领域中,奖励模型必须能够生成准确的奖励信号。
- 推理时可扩展性(Inference-time scalability): 当分配更多的计算资源进行推理时,奖励模型应该能够产生更高质量的奖励。
- 学习可扩展的行为(Learning scalable behaviors): 为了使奖励模型在推理时能够有效地扩展,它们需要学习能够随着计算资源的增加而提高性能的行为。
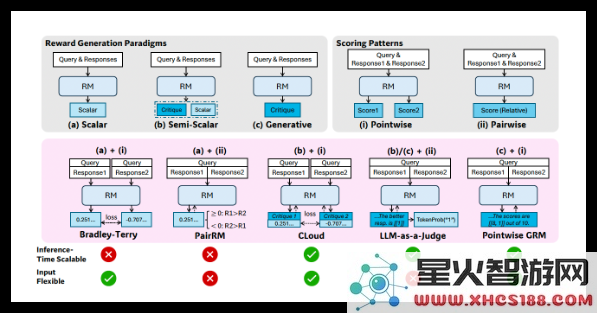
研究人员指出,“基于点的生成式奖励建模”(Pointwise Generative Reward Modeling,GRM),即模型生成文本评论并从中导出分数的方法,能够为通用任务提供所需的灵活性和可扩展性。DeepSeek 团队在 GPT-4o 和 Gemma-2-27B 等模型上进行的初步实验表明,“某些原则可以指导生成式奖励模型在适当的标准内生成奖励,从而提高奖励的质量”,这启发了他们可以通过扩展高质量原则和准确评论的生成来实现奖励模型的推理时可扩展性。
SPCT的核心机制:自主演原则与批判调优
基于以上发现,DeepSeek 团队开发了SPCT技术,该技术训练GRM根据查询和回复动态地生成原则和评论。研究人员认为,原则应该是“奖励生成的一部分,而不是一个预处理步骤”。通过这种方式,GRM可以根据其正在评估的任务即时生成原则,然后基于这些原则生成批判性意见。

SPCT包含两个主要阶段:
- 拒绝式微调(Rejective fine-tuning): 此阶段训练GRM使用正确的格式为各种输入类型生成原则和评论。模型为给定的查询/回复生成原则、评论和奖励。只有当预测的奖励与真实情况(例如,正确识别出更好的回复)一致时,生成的轨迹才会被接受,否则将被拒绝。这个过程会重复进行,模型在过滤后的示例上进行微调,以提高其原则/评论生成能力。
- 基于规则的强化学习(Rule-based RL): 在此阶段,模型通过基于结果的强化学习进行进一步的微调。GRM为每个查询生成原则和评论,奖励信号基于简单的准确性规则计算(例如,是否选择了已知的最佳回复)。然后更新模型,鼓励GRM学习如何动态且可扩展地生成有效的原则和准确的评论。
为了应对推理时可扩展性的挑战,研究人员对同一输入多次运行GRM,生成不同的原则和评论集。最终的奖励通过投票(聚合样本分数)确定。这使得模型能够考虑更广泛的视角,从而在获得更多资源时产生更准确和细致的最终判断。
此外,为了解决一些生成的原则/评论可能质量不高或存在偏差的问题,研究人员引入了一个“元奖励模型”(meta RM)——一个单独的、轻量级的标量RM,专门用于预测主要GRM生成的原则/评论是否可能导致正确的最终奖励。在推理过程中,元RM评估生成的样本并过滤掉低质量的判断,进一步提高了扩展性能。
DeepSeek-GRM的卓越表现
研究人员将SPCT应用于谷歌的开源模型Gemma-2-27B,创建了DeepSeek-GRM-27B。在多个基准测试中,他们将其与几种强大的基线RM(包括LLM-as-a-Judge、标量RM和半标量RM)以及公开模型(如GPT-4o和Nemotron-4-340B-Reward)进行了评估。结果表明,DeepSeek-GRM-27B优于在相同数据上训练的基线方法。

与标准微调相比,SPCT显著提高了奖励的质量,更重要的是,提升了推理时的可扩展性。通过生成更多样本进行推理时扩展,DeepSeek-GRM-27B的性能大幅提升,甚至超过了更大的模型,如Nemotron-4-340B-Reward和GPT-4o。元RM的引入进一步提升了扩展性,通过过滤判断实现了最佳结果。研究人员指出:“通过更大规模的采样,DeepSeek-GRM可以根据更多样化的原则做出更准确的判断,并输出更精细的奖励。”有趣的是,与在可验证任务上表现良好但在其他方面表现较差的标量RM相比,SPCT在不同领域表现出更少的偏差。
更通用和可扩展的奖励模型的开发对于企业级AI应用具有广阔的前景。潜在的受益领域包括创意任务以及模型必须适应动态环境(如不断变化的客户偏好)的应用。
尽管取得了显著的成果,但与非生成式RM相比,DeepSeek-GRM在纯粹可验证的任务上的性能以及效率方面仍然存在挑战。DeepSeek 团队表示,未来的工作将侧重于提高效率和更深入的集成。他们总结道:“未来的方向可能包括将GRM集成到在线RL流程中,作为奖励系统的通用接口,探索与策略模型进行推理时协同扩展,或者作为基础模型的鲁棒离线评估器。”
论文:https://arxiv.org/abs/2504.02495
最新星火攻略
更多- 文明7夏威夷文明特性及力量解析 深化游戏战略以抢占胜利先机
- 法版健身瑜伽3满天星:在繁忙生活中寻找身心平衡与内在平静的最佳选择
- 我叫MT2:经典再来也开启新的冒险与策略旅程,感受奇幻世界的无限可能性
- 震撼发布:斯坦福2025 AI指数显示中美人工智能差距缩小至0.3%,全球科技竞争已达白热化阶段
- 探寻和平精英中的彩虹独角兽:全新独特体验大揭秘,带你领略不一样的游戏世界
- DeepCoder-14B震撼发布:开源AI编程利器对标o1与o3-mini,开启技术领域新篇章
- 针对喋血复仇游戏中的乱码问题提出的切实可行的解决方案与技巧
- 英伟达推出Llama3.1 Nemotron Ultra 253B,性能显著领先于Llama 4 Behemoth,引发业界关注
- 魔兽世界11.0版本 酒仙武僧高效PVE输出技巧与实用手法全面指南
- 英伟达重磅推出Llama 3.1 Nemotron Ultra 253B:重塑AI性能的行业标杆再创辉煌
- LOL3月份幸运召唤师活动具体地址及参与方式的详细介绍
- 英伟达推出Llama 3.1 Nemotron Ultra 253B:新的技术标杆,展现卓越性能与创新潜力
- Cloudflare推出全新AutoRAG:简化AI上下文感知开发的全托管RAG解决方案
- 坎公骑冠剑:提升灵魂点数上限的实用技巧与攻略分享
- 阶跃星辰正式推出全新多模态推理模型——Step-R1-V-Mini,为智能应用带来更多可能性
最新星火智能
更多- 原神联动活动详解:如何在游戏中获得异世界救世主埃洛伊的完整步骤解析
- 全新开源模型 DeepCoder:实现极致编程效率,力压 OpenAI o1 模型的潜力与性能
- LOL一月幸运召唤师活动全方位深度解析与参与指南,骑士们准备好迎接挑战了吗?
- NS2与NS卡带的兼容性探讨:揭示Nintendo Switch如何处理旧款游戏卡带的兼容性挑战
- 网信办:至2025年3月31日已有346款生成性人工智能服务完成备案登记工作
- 剑网3指尖江湖:全面解析快速提高战力的多种有效策略与方法
- AI虚拟化身推动技术创新浪潮:生成模型为多元化应用开启新视野
- 深入星露谷物语的探险:成功献祭沙漠柱子的实用技巧与策略指南
- Deep Research正式推出Gemini 2.5 Pro:谷歌最新的AI智能模型引领科技潮流
- 燕云十六声:扇子武学的偷师秘籍与实用攻略分享
- DNF忍者觉醒深入解析:技能特点、玩法策略及角色发展全方位分析
- SiteMCP:一款将普通网站转变为功能强大的MCP服务器的创新解决方案
- 魔兽世界:轻松获取战地修理机器人110G图纸的高效攻略与技巧分享
- 抖音宣布推出辟谣卡功能:将人工审核与AI大模型技术相结合以提升辟谣准确性
- 魔兽世界MC中的灭火任务全攻略详解,助你轻松完成挑战
最新星火游戏
更多